
Introduction: Why Data Pipeline Architecture Matters in 2026
In today’s fast-paced business world, data is growing at an unprecedented rate. Organisations are collecting enormous amounts of information every day—from customer interactions to operational metrics. Managing this data effectively is no longer optional; it is essential for making informed decisions, improving customer experiences, and staying ahead of competitors.
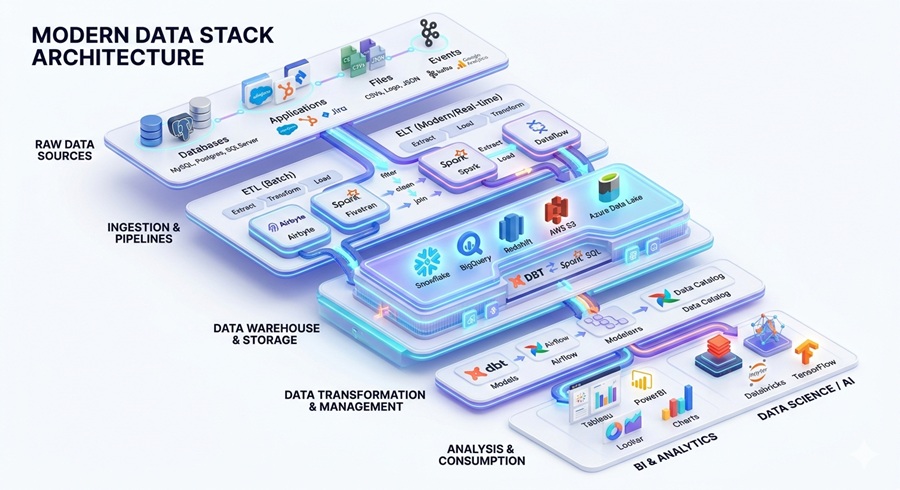
This is where data pipeline architecture comes into play. A well-designed data pipeline ensures that raw data is efficiently collected, processed, and delivered to the right systems for analysis. With the rise of real-time analytics and AI-driven insights, businesses need pipelines that are not only reliable but also flexible enough to handle massive data volumes and complex transformations.
One of the most important choices organisations face today is deciding between ETL vs ELT approaches. Both methods are widely used for moving and transforming data, but they serve different purposes and suit different types of workloads. Understanding the strengths and limitations of each can dramatically improve the speed, accuracy, and usability of your data.
In this guide, we will explore the ETL vs ELT comparison in detail, helping you understand which architecture works best for modern businesses in 2026. You will learn how each method impacts performance, scalability, and data analytics, so you can make smarter decisions for your organisation’s data strategy.
At Cor Advance Solutions, we specialise in AI, machine learning, and modern data infrastructure. Our expertise in designing efficient modern data pipelines allows businesses to leverage their data fully, enabling actionable insights and smarter decision-making. By the end of this article, you’ll have a clear understanding of ETL and ELT, and which approach is right for your business needs.

2. Understanding Data Pipelines in Modern Data Engineering
What Is a Data Pipeline?
A data pipeline is a set of processes that moves data from its source to a place where it can be analysed and used. Simply put, data flows from the point it is collected, through stages of processing and transformation, and finally into analytics systems or dashboards. For example, customer information from a website might travel through a pipeline to clean, organise, and enrich the data before it appears in a report that helps businesses make smarter decisions.
Why Data Pipelines Are Critical for Businesses
In today’s digital world, businesses rely on modern data pipelines to stay competitive. Here’s why they are so important:
- Data-driven decision making: Pipelines provide reliable, timely data that decision-makers can trust. This helps companies respond faster to market trends and customer needs.
- Business intelligence and analytics: Clean, organised data fuels reports, dashboards, and analytics tools that reveal patterns and insights that were previously hidden.
- AI and machine learning workflows: Advanced technologies like AI and machine learning need large volumes of accurate data. Pipelines ensure that the right data is available in the right format for these systems to learn and perform effectively.
Evolution of Data Architecture
Over the years, data management has evolved to meet growing business demands:
- Traditional data warehouses: Early systems stored structured data in centralised warehouses. They were reliable but often rigid and slow for large-scale or real-time analytics.
- Cloud-native data platforms: Cloud solutions allow businesses to scale quickly, process massive data volumes, and access data from anywhere. These platforms are more flexible and cost-efficient than traditional warehouses.
- AI-powered data ecosystems: The latest approach integrates modern data pipelines with AI and machine learning tools. These ecosystems automate data collection, transformation, and analysis, enabling businesses to gain insights in real-time and make predictive decisions.
By understanding data engineering architecture and the role of modern pipelines, organisations can build systems that are scalable, efficient, and ready for the AI-driven future. Investing in the right pipeline strategy ensures that data is not just collected, but truly harnessed to create business value.
3. What Is ETL? (Extract, Transform, Load)
Definition of ETL
ETL stands for Extract, Transform, Load. It is a classic method used to move data from different sources into a central system, usually a data warehouse. In simple terms, ETL takes raw data, cleans and organises it, and stores it in a format that is easy to analyse. This makes it a core part of many ETL pipelines in modern businesses.
How the ETL Process Works
The ETL process works in three main steps:
- Extract – Data is collected from multiple sources such as databases, APIs, or business applications.
- Transform – The extracted data is cleaned, structured, and converted into a consistent format suitable for analysis.
- Load – The processed data is loaded into a data warehouse, ready for reporting, analytics, or business intelligence tools.
This step-by-step workflow ensures that data is accurate, complete, and usable for decision-making.
Key Components of ETL Architecture
A typical ETL architecture includes:
- Data sources – The origin of raw data, such as transactional databases, CRM systems, or external APIs.
- ETL processing engine – The tool or system that handles data extraction, transformation, and loading.
- Transformation layer – Where data is cleaned, normalised, and enriched for analysis.
- Data warehouse – The central repository where processed data is stored and made accessible for reporting and analytics.
Popular ETL Tools Used by Enterprises
Businesses rely on several powerful tools to build and manage ETL pipelines, including:
- Informatica PowerCenter – Known for its robust enterprise-level features and strong data governance.
- Talend – An open-source option with flexible integration and transformation capabilities.
- Apache NiFi – Ideal for handling data flows in real-time and across complex environments.
Advantages of ETL
The ETL approach offers several benefits:
- Strong data quality and validation – Ensures clean, accurate, and reliable data.
- Better governance and control – Makes it easier to track data lineage and compliance.
- Ideal for structured enterprise reporting – Perfect for standardised reports and dashboards.
Limitations of ETL
However, ETL is not without drawbacks:
- Slower for large datasets – Processing big data can take time due to transformations before loading.
- High infrastructure cost – Traditional ETL often requires expensive servers and storage.
- Limited flexibility for modern analytics – Less suitable for real-time analysis or unstructured data.
In summary, the ETL process is a proven approach for structured data management, offering strong control and reliability, but it may struggle with speed and flexibility in today’s dynamic, modern data pipelines.
4. What Is ELT? (Extract, Load, Transform)
Definition of ELT
ELT stands for Extract, Load, Transform. It is a modern approach to moving data that became popular with the rise of cloud data platforms. Unlike ETL, ELT loads raw data first into a central storage system and then transforms it within that system. This approach leverages the power of cloud computing, making it faster and more flexible for ELT pipelines in today’s modern data pipelines.
How ELT Works
The ELT process follows three main steps:
- Extract – Data is collected from various sources such as applications, databases, or APIs.
- Load – Raw data is loaded directly into a cloud data warehouse or a data lake, without heavy transformations upfront.
- Transform – Data is then transformed inside the warehouse or lake using the system’s compute resources, ready for analytics, AI, or reporting.
This workflow allows businesses to handle larger volumes of data more efficiently and supports faster analytics.
Core Components of ELT Architecture
A typical ELT architecture consists of:
- Cloud data warehouse – The main storage and compute engine for data processing.
- Data lake storage – Stores large amounts of raw, unstructured, or semi-structured data.
- Transformation engine – Performs the necessary calculations, cleansing, and structuring of data inside the warehouse.
- Analytics layer – Provides tools for reporting, dashboards, and advanced analytics.
Popular ELT Tools
Several tools help businesses build and manage effective ELT pipelines, including:
- Fivetran – Automates data extraction and loading with minimal setup.
- dbt – Handles transformations inside the data warehouse, making workflows reproducible and manageable.
- Airbyte – An open-source solution for extracting and loading data from a wide range of sources.
Advantages of ELT
The ELT model offers key benefits:
- Faster data processing – Data is available for transformation immediately, reducing delays.
- Highly scalable architecture – Cloud platforms can easily handle large datasets without slowing down performance.
- Ideal for big data analytics and AI workloads – Supports complex, real-time analytics and machine learning applications.
Limitations of ELT
Despite its advantages, ELT has some challenges:
- Requires powerful cloud infrastructure – Processing large volumes of raw data needs significant compute resources.
- Raw data governance challenges – Storing untransformed data can create security and compliance concerns if not managed properly.
In short, ELT architecture is well-suited for modern, cloud-based data environments. It enables fast, scalable processing, making it ideal for AI, machine learning, and modern data pipelines, while also demanding careful planning around infrastructure and governance.
5. ETL vs ELT: Key Differences Explained
Understanding the difference between ETL vs ELT is essential for choosing the right approach for your modern data pipelines. While both methods move data from sources to analytics systems, they differ in when and where data is transformed, how they handle data volumes, and how they impact costs and performance.
Here’s a quick comparison for clarity:
| Feature | ETL | ELT |
| Transformation Stage | Before loading | After loading |
| Processing Location | ETL server | Data warehouse / cloud |
| Data Format | Structured | Raw + structured |
| Performance | Slower for large datasets | Faster and highly scalable |
| Cost Efficiency | Higher infrastructure cost | Optimised for cloud computing |
What Makes ETL Different
In ETL, data is transformed before it reaches the warehouse. This ensures high data quality, strong governance, and standardised reporting. However, ETL can be slower and more expensive, especially when handling large datasets or modern analytics workloads.
What Makes ELT Different
ELT transforms data after it is loaded into a cloud warehouse or data lake. This approach is faster, highly scalable, and better suited for big data analytics and AI workloads. ELT reduces infrastructure costs for large datasets but requires careful governance of raw data.
Quick Takeaway
The key difference is simple: ETL is ideal for structured, enterprise reporting where control and data quality are critical, while ELT is perfect for cloud-native, scalable analytics environments where speed and flexibility matter. Choosing between ETL vs ELT depends on your data size, processing needs, and the type of analytics your business wants to perform.
6. Why ELT Is Becoming the Preferred Architecture in 2026
In recent years, businesses have been shifting from traditional ETL pipelines to ELT pipelines. The change is driven by the rise of cloud computing and the need for faster, more scalable data processing. In 2026, ELT is emerging as the preferred choice for companies looking to build a modern data stack that supports advanced analytics and AI workflows.
Key Drivers of the Shift
Several factors are pushing organisations toward ELT architecture:
- Rise of cloud data warehouses – Platforms like Snowflake, Google BigQuery, and Amazon Redshift allow businesses to store and process large amounts of data without maintaining expensive on-premise infrastructure.
- Cheaper storage and scalable compute – Cloud technology makes it cost-effective to store raw data and scale processing power as needed, enabling businesses to handle big data efficiently.
- Real-time data analytics – ELT pipelines can load data first and transform it on demand, supporting near-instant insights for decision-making and operational efficiency.
- Growth of AI and machine learning pipelines – Modern analytics and AI models require access to raw and structured data in large volumes. ELT enables seamless data preparation for these workflows.
Leading Cloud Data Platforms Supporting ELT
Several cloud platforms make ELT easier and more powerful:
- Snowflake – Offers a cloud-native architecture that separates storage and compute, making ELT workflows faster and more flexible.
- Google BigQuery – Handles massive datasets in real-time, supporting complex transformations and analytics directly in the warehouse.
- Amazon Redshift – Provides scalable storage and processing for structured and semi-structured data, ideal for modern cloud data architecture.
In 2026, the combination of cloud computing, advanced analytics, and AI has made ELT pipelines the backbone of the modern data stack. Organisations adopting ELT benefit from faster insights, greater flexibility, and the ability to scale effortlessly with growing data volumes.
7. ETL vs ELT Performance Comparison
When choosing between ETL vs ELT for your data pipeline architecture, understanding how they perform is one of the most important factors. In 2026, the speed, scalability, and cost of data processing are key considerations for every business dealing with big data and real‑time analytics.
Data Processing Speed
- ETL relies on batch transformations – In traditional ETL, data is first extracted, then transformed before it is loaded. This sequential approach can create delays, especially with very large datasets, because each step must finish before the next begins. Research shows that batch processing in ETL can take hours for billions of rows of data, creating bottlenecks before loading into the target system.
- ELT uses distributed compute power – In ELT, raw data is loaded first into the data warehouse or cloud data architecture, and then transformed using the warehouse’s powerful compute engines. Modern cloud platforms like Snowflake, BigQuery, and Redshift support parallel processing, which makes ELT much faster and more scalable.
This means that for real‑time or near‑real‑time insights, ELT can deliver data much quicker, allowing analysts and AI models to work with fresh information.
Handling Big Data
- ETL struggles with extremely large datasets – Because ETL performs transformations before loading, it needs strong intermediate servers and often fails to scale efficiently for petabyte‑level data workloads without significant investment. Traditional ETL is best suited to structured, predictable data.
- ELT handles petabyte‑scale analytics – ELT architectures benefit from elastic cloud compute and storage. As data volumes grow, ELT scales without major redesign. Cloud platforms can execute transformations across many nodes at once, making ELT ideal for big data analytics, AI pipelines, and advanced use cases.
Infrastructure Cost
- ETL requires dedicated servers – Traditional ETL pipelines rely on separate processing engines or staging environments, which need ongoing maintenance and hardware resources. This increases infrastructure costs, especially when scaling up for larger workloads.
- ELT leverages scalable cloud infrastructure – With ELT, the need for separate transformation servers disappears. Raw data is loaded into cloud warehouses, and transformations are done using cloud compute that can expand or shrink as needed. According to recent industry analysis, cloud data warehouse revenue represents over 70 % of the data integration market, showing how organisations prefer cloud costs that scale with use.
This pay‑as‑you‑go model means businesses only pay for compute when they need it, reducing idle infrastructure costs and improving overall efficiency.
8. Best Use Cases for ETL
While modern ELT pipelines dominate cloud environments, ETL remains highly relevant for specific use cases. Organisations continue to rely on ETL where data governance, quality, and structured reporting are critical.
Situations Where ETL Performs Best
- Financial systems and compliance reporting – Banks, insurance companies, and investment firms require strict data control for audits and regulatory reporting. ETL’s approach of transforming data before loading ensures accuracy, consistency, and adherence to compliance standards.
- Healthcare data management – Patient records and medical data demand precision, privacy, and compliance with regulations like HIPAA. ETL pipelines enforce strong validation rules during transformation, reducing errors before data reaches reporting systems.
- Legacy enterprise environments – Many large organisations still operate on traditional on-premises systems. ETL works well with structured, predictable datasets, providing stability for mission-critical operations.
- Highly structured datasets – Any scenario where data comes in consistent, tabular formats benefits from ETL’s pre-loading transformations, ensuring clean, standardised information for analytics and reporting.
Why Transformation Before Loading Matters
Transforming data before loading gives organisations tighter control over data quality. It allows validation, cleansing, and standardisation at the source, reducing errors downstream. This is crucial for industries where mistakes can be costly, such as finance or healthcare.
Additionally, ETL’s pre-load transformation improves governance. Organisations can enforce business rules, access permissions, and compliance policies before data reaches central systems, making auditing and reporting simpler and more reliable.
9. Best Use Cases for ELT
Modern ELT pipelines are designed for speed, scalability, and flexibility, making them ideal for handling big data and cloud-native environments. Unlike ETL, ELT transforms data after loading, enabling organisations to process massive volumes quickly and run complex analytics without bottlenecks.
Modern Use Cases for ELT
- Big data analytics – ELT can process petabytes of raw and structured data efficiently, making it perfect for analysing large datasets in real time or near real time.
- SaaS product analytics – Cloud-native ELT pipelines allow SaaS companies to track user behaviour, feature adoption, and engagement metrics across multiple applications with minimal delay.
- AI and machine learning pipelines – ELT provides direct access to raw and structured data in the warehouse, enabling machine learning models to train on fresh data without time-consuming pre-processing.
- Real-time business intelligence – By transforming data on-demand, ELT supports dashboards and reports that reflect the most current information, empowering faster decision-making.
Industries Rapidly Adopting ELT
- eCommerce – Online retailers rely on ELT for personalisation, customer analytics, and real-time inventory tracking.
- FinTech – Financial technology companies use ELT to analyse transactional data, detect fraud, and provide instant insights for customers.
- SaaS platforms – Software providers leverage ELT to integrate data from multiple products and deliver actionable insights to customers in real time.
- AI-driven companies – Organisations building AI solutions use ELT pipelines to handle massive datasets, enabling predictive analytics and intelligent automation.
In summary, ELT is ideal for modern data pipelines where speed, scalability, and real-time insights are essential. Its cloud-first approach allows organisations across multiple industries to innovate faster, leverage big data effectively, and support AI-driven decision-making.
10. Hybrid Data Pipelines: The Future Architecture
As organisations deal with more complex data environments, hybrid data pipelines are emerging as the future of modern data pipelines. A hybrid approach combines the best of ETL and ELT, allowing businesses to balance governance, performance, and scalability.
Combining ETL and ELT Approaches
In a hybrid pipeline, ETL is used for structured, critical, or regulated data, ensuring high-quality transformations before loading. ELT is applied to raw, large-scale, or real-time data, leveraging cloud compute power to process and transform data on-demand. This approach lets organisations tailor processing strategies based on data type, use case, and compliance requirements.
Benefits of Hybrid Pipelines
- Flexibility – Businesses can choose the most suitable processing method for each dataset, combining pre-load validation with post-load transformations.
- Scalability – Cloud-native ELT components allow pipelines to scale effortlessly with growing data volumes, while ETL ensures stability for mission-critical processes.
- Better governance – ETL segments maintain strong quality and compliance controls, while ELT segments provide agility for analytics and AI workloads.
Example Hybrid Pipeline Architecture
A typical hybrid architecture might look like this:
- Data Ingestion – Collect data from databases, APIs, applications, and IoT devices.
- Raw Storage – Load untransformed data into a cloud data warehouse or data lake.
- Transformation Layer – Apply ETL transformations to regulated datasets and ELT transformations for analytics-ready raw data.
- Analytics Layer – Provide cleaned, structured, and transformed data to BI tools, dashboards, and AI pipelines.
Hybrid pipelines represent the future of data architecture, allowing organisations to benefit from both ETL vs ELT advantages. They combine governance and quality with speed and scalability, enabling faster insights, AI readiness, and more resilient cloud data architectures.
11. Data Governance, Security, and Compliance Considerations
For modern businesses, data governance, security, and compliance are critical aspects of any data pipeline architecture. As organisations handle larger volumes of sensitive data, ensuring privacy, accountability, and traceability is not optional—it’s essential. Enterprise decision-makers must carefully plan their ETL and ELT pipelines to meet regulatory requirements and maintain trust.
Key Considerations
- Data Privacy Regulations – Organisations must comply with local and international regulations such as the General Data Protection Regulation (GDPR). These rules govern how personal data is collected, stored, processed, and shared. Non-compliance can lead to significant fines and reputational damage.
- Access Control – Restricting who can view or modify data is vital. Role-based access and strong authentication ensure only authorised users can access sensitive information. This applies to both ETL and ELT pipelines, especially in cloud environments.
- Audit Trails – Maintaining detailed records of data movement and transformations helps organisations demonstrate compliance and investigate issues. Audit trails also improve operational transparency and accountability.
- Data Lineage – Understanding the origin, transformation, and journey of each data element ensures accuracy and reliability. Data lineage helps teams trace errors, validate reports, and meet regulatory reporting requirements.
Governance Frameworks
Several industry-standard frameworks guide best practices for data governance and security:
- General Data Protection Regulation (GDPR) – Sets strict rules for data privacy and protection across the EU, influencing global practices for personal data handling.
- ISO Standards (e.g., ISO 27001) – Provide frameworks for information security management systems (ISMS), helping organisations build secure, auditable, and compliant pipelines.
Implementing strong governance and compliance measures is not just about avoiding fines—it improves data quality, builds trust with customers, and supports reliable analytics. When designing ETL or ELT pipelines, organisations should integrate governance and security into every stage, from ingestion and storage to transformation and analytics.
12. ETL vs ELT for AI and Machine Learning Pipelines
When building AI and machine learning (ML) pipelines, the choice between ETL vs ELT has a big impact on how quickly and effectively data teams can work. In 2026, ELT has become the preferred approach for most AI‑driven analytics because it handles large datasets better, supports feature engineering, enables real‑time data use, and works smoothly with modern analytics tools.
Why ELT Is Preferred for AI‑Driven Analytics
1. Handling Large Datasets for Model Training
AI and ML models need lots of data to learn patterns and make accurate predictions. ELT loads raw, unprocessed data directly into modern data warehouses or lakes, where powerful computing engines can transform it later. This allows teams to work with entire datasets without losing any detail early in the process—a key advantage over ETL’s rigid pre‑load transformations. ELT is designed to scale with data volumes that would slow traditional ETL pipelines.
2. Feature Engineering Pipelines
Feature engineering—the process of creating meaningful variables that improve ML models—is central to AI workflows. ELT supports iterative and flexible transformation inside cloud platforms like Snowflake, BigQuery, and Databricks, so data scientists can refine features without re‑ingesting data. Tools such as dbt seamlessly integrate with ELT workflows, enabling teams to version control and test feature logic just like software code.
3. Real‑Time Data Ingestion
Modern AI systems often depend on up‑to‑the‑minute data—for example, in personalised recommendations or fraud detection. ELT pipelines can ingest raw streams quickly and make data available for transformation on demand. This flexibility contrasts with ETL’s batch transformation, which adds latency and can delay models from accessing fresh data.
4. Integration with Modern Analytics Platforms
Cloud data warehouses and lakehouses are at the heart of today’s analytics and ML ecosystems. ELT naturally integrates with these platforms, letting teams use native SQL and distributed processing systems to transform data without separate infrastructure. This setup simplifies workflows and lowers maintenance, while also enabling advanced analytics and AI experimentation directly where the data lives.
What This Means for AI and ML Workloads
- Flexibility: ELT lets teams explore raw and semi‑structured data first, then refine it later—crucial when data requirements change quickly during model development.
- Speed: Loading raw data quickly enables multiple ML experiments to run without re‑ingesting data each time.
- Scale: Cloud platforms can scale transformations using distributed compute resources for very large datasets, making ELT ideal for big data analytics and AI.
In simple terms, while ETL still has a role in tightly controlled environments or where data must be pre‑cleaned for compliance, ELT architecture offers the speed, flexibility, and scalability that AI and machine learning pipelines require in 2026. By loading raw data first and transforming it where it sits, businesses can train better models, build richer feature pipelines, and deliver real‑time insights with less friction.
13. How to Choose the Right Data Pipeline Architecture
Choosing between ETL vs ELT is one of the most important decisions for CTOs, data engineers, and enterprise leaders. The right data pipeline architecture ensures efficiency, scalability, and compliance while supporting business goals. Below is a practical framework to help organisations make the right choice.
Decision Framework
Choose ETL if:
- Strict compliance is required – Industries like finance, healthcare, and government benefit from ETL’s pre-load transformations, which enforce data validation and regulatory governance.
- Structured data environment – ETL works best when datasets are predictable and highly structured, allowing transformations to be applied consistently before loading.
- Legacy systems dominate – Organisations with on-premises ERP, CRM, or warehouse systems often rely on ETL for stability and compatibility.
Choose ELT if:
- Using cloud data warehouses – ELT leverages modern cloud compute and storage, making it ideal for platforms like Snowflake, BigQuery, or Redshift.
- Handling big data analytics – ELT pipelines scale effortlessly for large or semi-structured datasets, supporting real-time or near-real-time insights.
- Building AI-driven platforms – Machine learning and AI workflows benefit from ELT’s raw-data-first approach, enabling flexible feature engineering and faster model training.
Decision Checklist for CTOs and Data Engineers
Use this checklist to evaluate your organisation’s needs:
- Data Volume & Variety – Are you working with structured, predictable datasets, or do you need to handle massive raw and semi-structured data?
- Compliance & Governance Needs – Do regulations require data to be validated and transformed before storage?
- Infrastructure & Cost – Do you have legacy on-premises servers, or are you ready to leverage cloud elasticity?
- Analytics Requirements – Do you need real-time dashboards, AI pipelines, or predictive analytics?
- Scalability & Flexibility – Will your data volumes grow rapidly, and do you need to experiment with new transformations frequently?
- Team Skills – Are your data engineers experienced with ETL tools, or is your team comfortable with SQL, dbt, and cloud-native ELT workflows?
Summary Recommendation
- ETL: Best for compliance-heavy, structured, and legacy environments where governance is paramount.
- ELT: Best for cloud-first, large-scale, AI and ML-driven workflows that demand speed, scalability, and flexibility.
- Hybrid Pipelines: Consider combining ETL and ELT if you need governance for critical data while also supporting large-scale analytics and AI workloads.
By following this decision framework and checklist, organisations can choose the data pipeline architecture that balances performance, compliance, and innovation for 2026 and beyond.
14. Market Adoption & Growth Trends of Data Pipeline Tools
The global data pipeline tools market is booming. By 2030, it is projected to reach $48.33 billion, growing at a remarkable 26.8% CAGR from 2026 to 2030. This growth reflects the urgent need for organisations to process ever-increasing volumes of data. Cloud-based deployments dominate, capturing 71.18% of market revenue, while traditional on-premises solutions decline as cloud-native modern data stacks become the default choice for new implementations.
ETL vs ELT Market Trends
- The ETL software market is growing steadily from $4.87 billion to $9.16 billion by 2028 (17.1% CAGR). While ETL remains significant, ELT and real-time pipeline segments are growing faster due to the shift to cloud data warehouses. Legacy ETL vendors face pressure to modernise or risk losing relevance.
- North America leads the global market with 40.15% share, driven by early cloud adoption and mature digital infrastructure. The region’s market size reached $6.25 billion in 2026, with Silicon Valley acting as a hub for innovation. Europe follows with steady growth, and Asia Pacific shows strong regional expansion.
- Large enterprises account for roughly 72% of market revenue, using hybrid approaches that combine ETL for legacy systems with ELT for cloud workloads. Meanwhile, SMEs are the fastest-growing segment, leveraging cloud-native ELT tools that reduce barriers to entry.
- By 2026, 52% of companies have migrated most IT environments to the cloud, enabling large-scale ELT adoption. Within 18 months, 63% of organisations expect cloud-majority infrastructure, fundamentally transforming data integration economics.
Performance & Efficiency Insights
Modern ELT architectures offer dramatic improvements in speed and efficiency:
- Snowflake delivers up to 40% faster query performance over 26 months of stable workloads, thanks to automatic clustering and query optimisation.
- Databricks processes 32.9 million queries per hour at 100TB scale, outperforming previous records by 2.2x while reducing costs by 10%, verified by TPC-DS benchmarks.
- BigQuery provides serverless analytics, processing terabytes in seconds and petabytes in minutes, eliminating capacity planning challenges.
- Organisations report 50–90% reductions in processing time after adopting ELT, enabling near-real-time data availability for analytics and AI workflows.
- Modern ELT tools reduce data preparation time by 40–60%, freeing data engineers to focus on value-adding analysis.
- Real-time ELT pipelines improve fraud detection from hours to minutes, demonstrating clear business impact.
Cost & ROI Considerations
- ELT cost structures differ from ETL. While cloud compute costs may offset some infrastructure savings, organisations report 30–40% overall cost reductions when optimised correctly.
- Cloud adoption drives high ROI, with IDC studies reporting up to 222% ROI for SMBs on platforms like Google Cloud. Public sector organisations report measurable savings through improved data sharing and reduced duplication.
- Pricing models vary: platforms like Fivetran charge based on Monthly Active Rows (MAR), while others like Stitch use different models. Understanding consumption-based costs is essential for managing budgets.
Industry-Specific Adoption
- Financial services adopt hybrid approaches: ELT for real-time analytics and fraud detection, ETL for regulatory reporting.
- Healthcare data integration market will reach $35.5 billion by 2032, balancing strict compliance with advanced analytics.
- Technology companies lead in ELT adoption, with cloud-native infrastructures enabling rapid innovation.
- Manufacturing and retail use hybrid strategies for IoT sensors and real-time analytics while maintaining batch processing for ERP systems.
- Energy and telecommunications leverage ELT for smart grid management and network optimisation.
- Education uses modern pipelines for real-time student performance tracking and personalised learning.
Platform & Vendor Insights
- Snowflake: ~$3.5 billion in product revenue, 30% YoY growth, driving ELT adoption.
- Databricks: Strong position in lakehouse architecture, combining warehouse performance with data lake flexibility.
- Fivetran: $300 million ARR, 50% YoY growth, reducing pipeline development by 95% for customers.
- AWS Glue, Azure Data Factory, and Google BigQuery dominate cloud integration, with serverless and hybrid capabilities.
- Open-source Apache Spark remains widely adopted for flexible ETL/ELT implementations.
Future Trends
- AI-powered tools are increasing productivity in integration workflows.
- Edge computing is expected to generate 75% of enterprise data by 2026, requiring distributed processing approaches.
- Hybrid cloud adoption will reach 90% by 2027, combining on-premises and cloud systems.
- Data mesh and data fabric markets are expanding rapidly, supporting decentralised ownership and automated integration across environments. Source
15. Frequently Asked Questions
Q1: What is the difference between ETL and ELT?
ETL (Extract, Transform, Load) processes data by transforming it before loading into a warehouse, making it ideal for structured, compliance-heavy environments. ELT (Extract, Load, Transform) loads raw data first and transforms it inside the warehouse, offering faster processing and flexibility for large datasets and modern analytics.
Q2: Which is better, ETL or ELT in 2026?
In 2026, ELT is generally better for cloud-first, AI-driven, and big data workloads due to its speed, scalability, and seamless integration with modern data pipelines. ETL remains valuable for legacy systems and strict regulatory environments where pre-load transformations and governance are critical.
Q3: Is ELT replacing ETL completely?
No, ELT is not fully replacing ETL. Many organisations use hybrid pipelines that combine ETL for compliance or structured datasets with ELT for cloud, AI, and real-time analytics. ETL continues to serve industries where data quality, validation, and pre-load governance are essential.
Q4: Which architecture works best with cloud data warehouses?
ELT works best with cloud data warehouses because it leverages cloud compute and storage to process raw and structured data at scale. It enables real-time analytics, AI pipelines, and flexible feature engineering while reducing infrastructure complexity.
Q5: What tools support ETL and ELT pipelines?
Popular ETL tools include Informatica PowerCenter, Talend, and Apache NiFi, while ELT pipelines often use Fivetran, dbt, and Airbyte. Many modern platforms like Snowflake, Databricks, and BigQuery support both approaches, enabling hybrid architectures for flexible and scalable data pipeline architecture.
16. Conclusion: Choosing the Right Data Pipeline Architecture
In 2026, selecting the right data pipeline architecture is crucial for business success. ETL remains vital for structured enterprise workflows, ensuring governance, compliance, and high-quality reporting. Meanwhile, ELT dominates modern cloud-based analytics ecosystems, providing speed, scalability, and flexibility for big data and AI-driven platforms.
For many organisations, hybrid pipelines offer the best of both worlds—combining ETL’s pre-load control with ELT’s cloud-native performance. Businesses should choose their architecture based on data volume, infrastructure capabilities, and analytics objectives, ensuring alignment with both operational and strategic goals.
At Cor Advance Solutions, we help enterprises design and implement cutting-edge AI, machine learning, and data engineering solutions, guiding organisations to build modern, efficient, and scalable data pipeline architectures that deliver real business value.
